
In this post, I’ll explain one of the biggest privacy issues in the AI industry at present, and the practicality of one magical solution.
The Problem: AI Privacy
In a typical AI model that runs in the cloud, we take our inputs, such as a question about our homework, and send it to a server in the cloud. The server puts the input into a neural network, and the result comes out the other end. This result is then sent back to us.
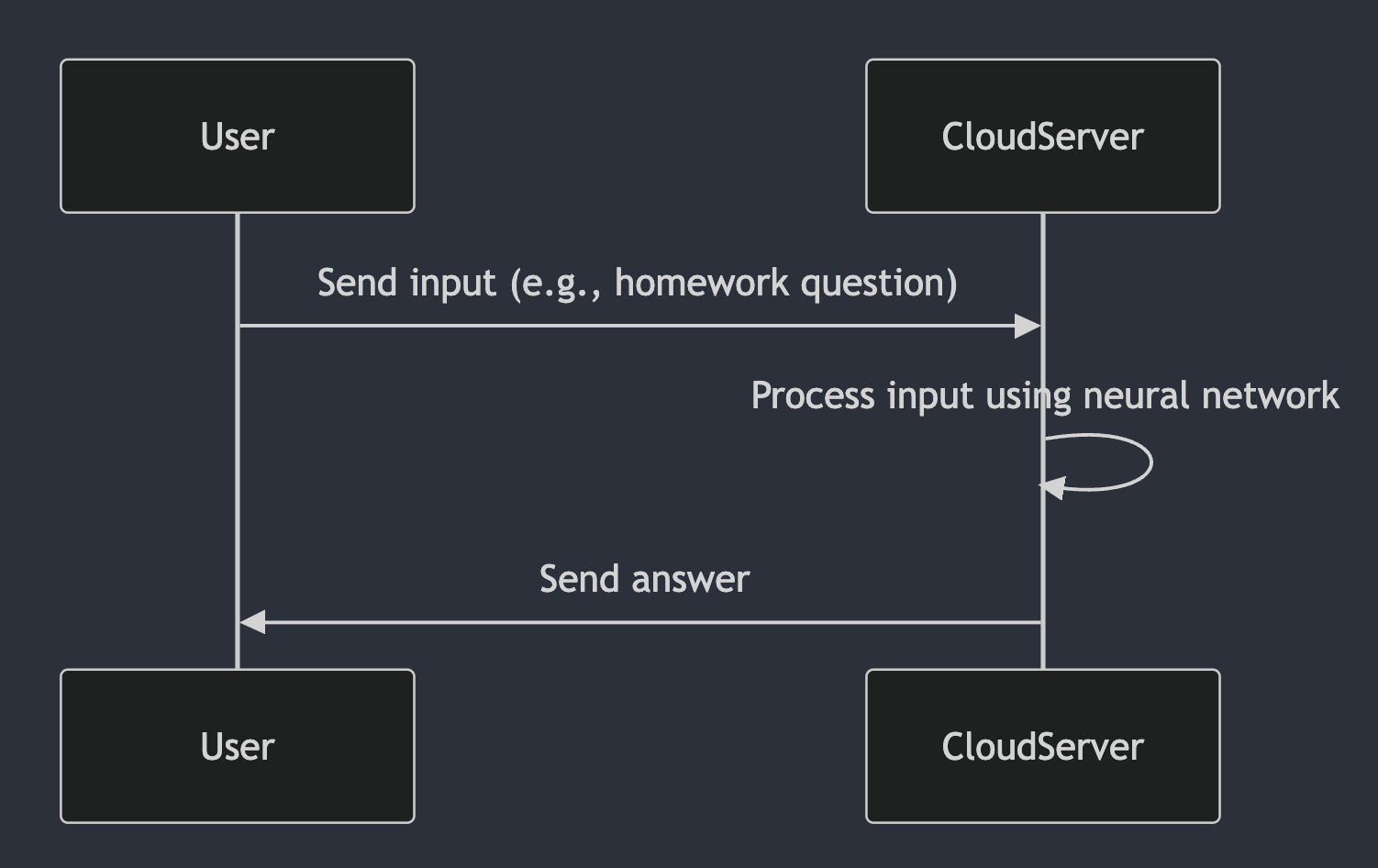
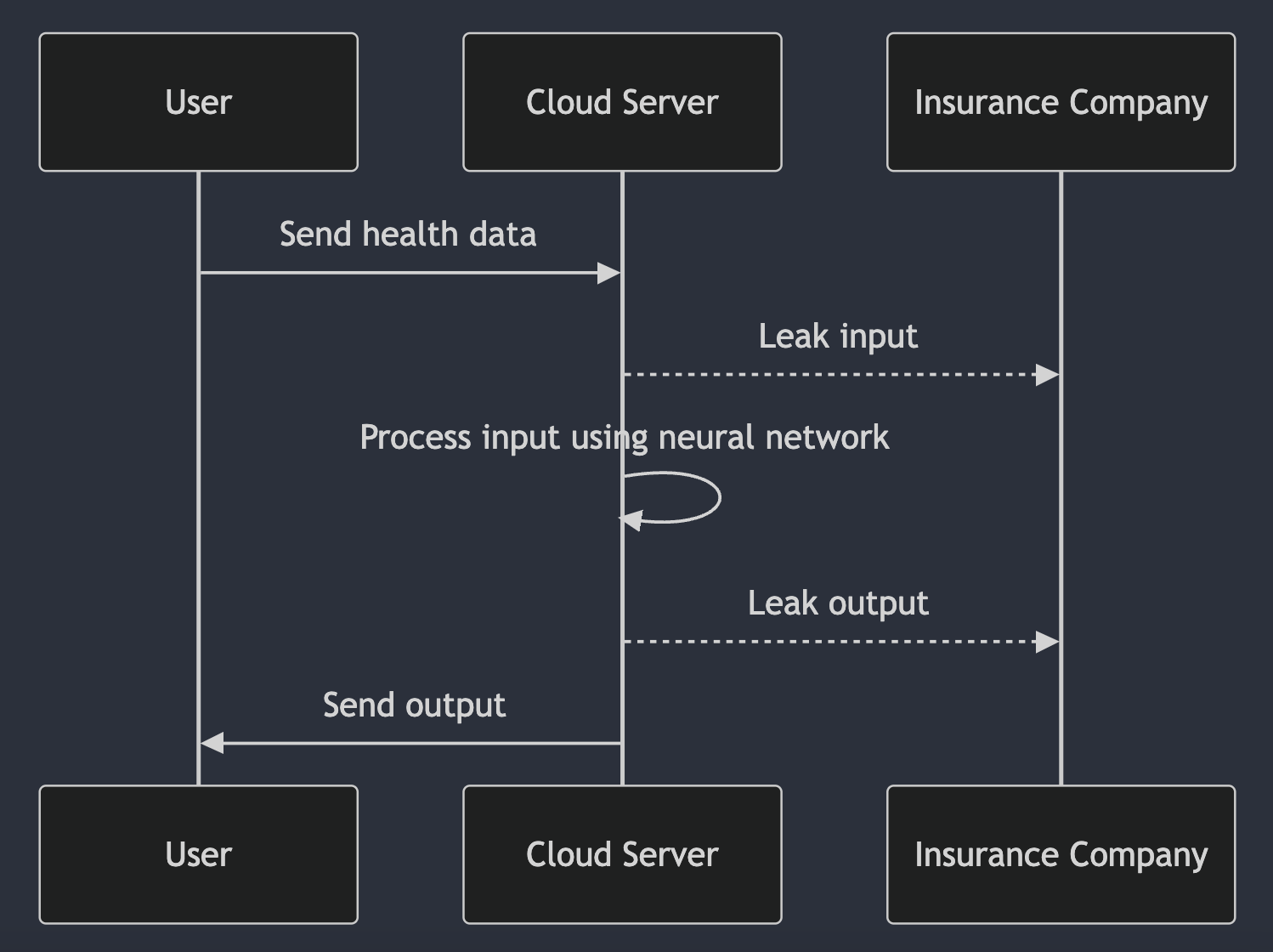
But this approach potentially allows the owner of the server, or a virus, to view and leak the input and output. For homework, this may not matter, but if it’s sensitive data about your health or your salary, then you could be in trouble.
Homomorphic Encryption
One solution to this issue is homomorphic encryption (HE). HE is a technology that allows servers to perform computation on encrypted data, without ever decrypting it. You encrypt your input while its on your machine, and send the encrypted input to the cloud. The computation runs on the encrypted input, producing an encrypted result which is sent back to you, and then you decrypt it in the safety of your home to view the result. The data was encrypted the whole time, so it’s impossible for it to be leaked. If a virus is watching the computations, all it can see is encrypted nonsense.
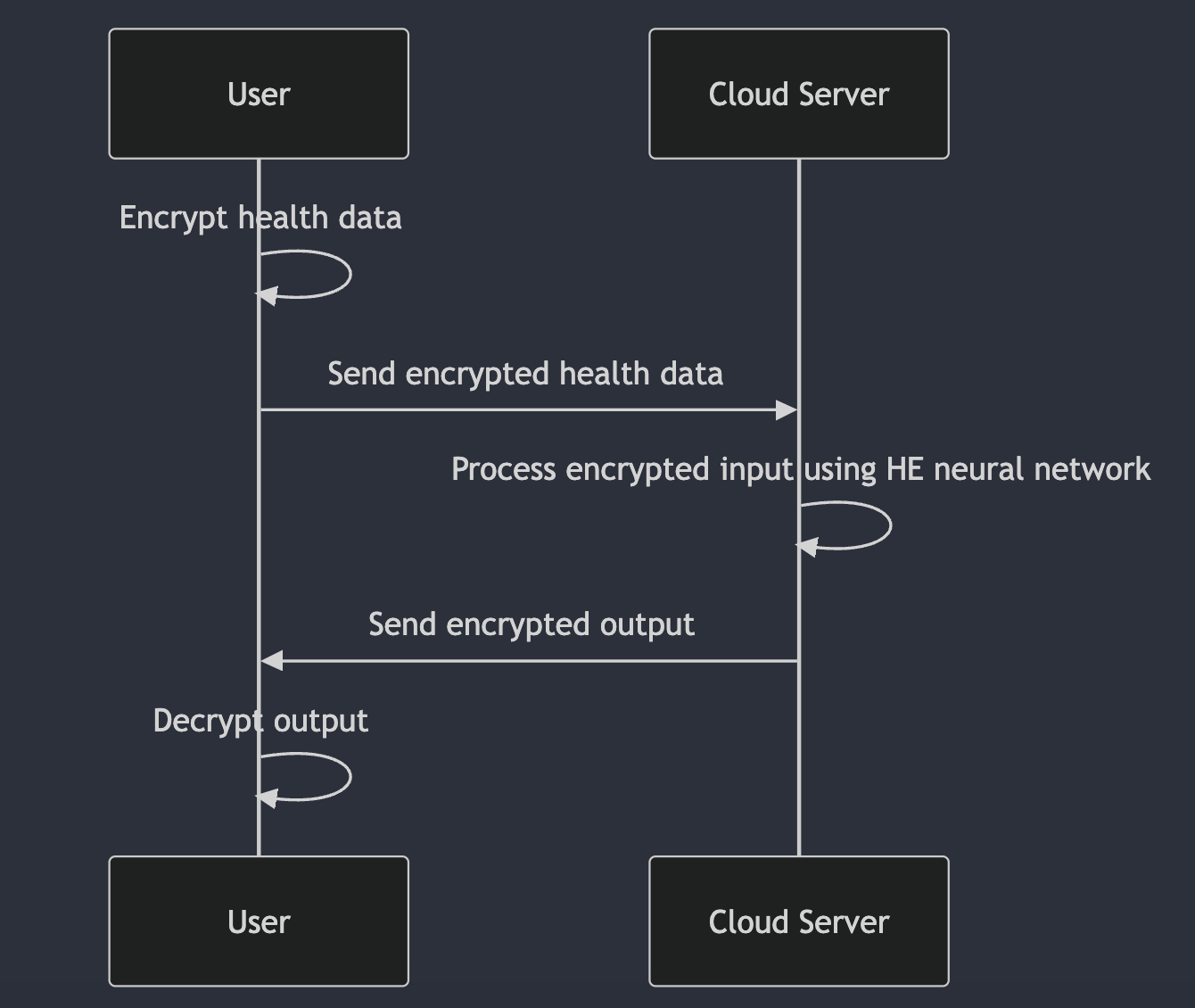
HE works by translating everything from the plaintext domain, where normal computation happens, into a ciphertext domain. Everything is encrypted in the ciphertext domain, including operations like additions and multiplications. It’s like magic, gifted to us by mathematics, and it actually works!
The Invisible Slug
The issue is that the computation is much slower. It’s like being granted the superpower of invisibility, but you are only allowed to move at the speed of a slug. But it is getting faster, and there’s tons of hype about it.
So if it’s getting faster, how fast is a HE neural network in 2024? Answering that is the goal of this blog post! There’s plenty of AI-generated slop online about how HE, the holy grail, is going to revolutionise AI, but I couldn’t find any posts explaining the current progress of HE neural networks.
How to turn my AI into HE AI?
Neural networks primarily consist of additions and multiplications. To convert to HE, these operations can be swapped out for their equivalents in the ciphertext space, and the associated parameters can be encrypted. For other parts of the neural network – such as activation functions – custom approximations are often used, such as polynomial functions.
This ability to translate a neural network into HE means that it can be trained in the plaintext space, at typical fast speeds, and then moved into the ciphertext space later for HE inference.
Automatic Translation
We now have compilers that can do this translation automatically. For example, the HE-MAN compiler can take in a standard neural network in ONNX format and run it as a HE neural network.
How fast is it?
As always with neural networks, the latency is determined by the hardware it is running on. To give you an initial perspective of how fast HE neural networks run on various hardware, I’ll show some examples from this systemization of knowledge paper from early 2024, which compared the performance of running a ResNet-20 using HE on GPU, FPGA, and ASIC. I’ll also include CPU:
- CPU: 23 minutes on 32 core CPU (from Craterlake paper, 2022)
- GPU: 316 seconds on NVIDA A100 (TensorFHE, when batching isn’t considered, 2022)
- FPGA: 2.6 seconds on Xilinx Alveo U280 (Poseidon, 2023)
- ASIC: 0.125 seconds (ARK, 2022)
These latencies may seem reasonable, but this neural network only has about 270k parameters. If part of your daily routine is to check if a 32x32 image consists of a cat or a dog, then yes, HE neural networks are practical for you! If your use of AI involves state-of-the-art LLMs such as ChatGPT, which have hundreds of billions of parameters (~1,000,000x), then no, they are not practical for you yet.
Who’s making it faster?
The results show that custom hardware, like ASICs, are our best hope for getting to practical speeds. DARPA also recognises this, and have been running a competition named DPRIVE since 2021 to drive research towards practical HE. It is currently in Phase 2, and there are three teams remaining: Intel, Niobium, and Duality.
Intel’s HERACLES system currently speeds up HE by more than three orders of magnitude (>1000x). Niobium have “simulation results” of a more than 5000x speedup, and Duality boast a 35,500x speedup. The teams are still secretive, understandably, and it’s not clear yet what their results will be for neural network applications. It seems that Phase 2 will be ending soon, and I’m excited to see the end-to-end results.
There are some other companies developing custom hardware for HE, such as Fabric and Cornami, but it’s hard to tell how far along they are.
Lack of high compute benchmarking
Considering speed is the blocker on bringing HE into production, I find it surprising that there is no leaderboard where teams aim for the highest inference speeds, using any software+hardware combination they want. This is how it works in the standard neural network industry, with MLPerf.
MLPerf contains benchmarks which show the fastest software+hardware combinations for training and running various AI models. It shows us what is currently possible when pushing the limits of compute power. For example, the fastest on the inference leaderboard (round v4.1) for running ResNet-50 (25M parameters) is a cluster of 8 NVIDIA H200 GPUs which can produce over 700k results per second. This cluster costs around $250,000.
When a company with big pockets in industry says I need to run ResNet-50 as fast as possible, and I don’t care how much it costs, they find an answer on MLPerf. Whereas if someone said that to the HE community, they would get: well, this framework can run ResNet-20 on one GPU in the fastest time, so maybe that’ll work best, but we’ve never tried it.
Need for Speed, not Need for Accuracy
HE computation accumulates noise, so de-noising operations are done periodically to reduce the noise level. However, these de-noising operations (named bootstrapping) have a massive latency cost.
Some HE frameworks aim for perfect accuracy at the cost of speed. In typical software, this would be necessary. For example, I don’t want my Google Drive to be inaccurate such that it delivers me someone else’s file every once in a while. However, neural networks are already noisy, so reducing their accuracy slightly to get faster outputs is fine in most cases.
Allowing accuracy degradation to achieve higher speeds is already done in regular neural networks when performing optimizations, such as quantizing an existing model. For this reason, I think the HEPerf benchmark would also benefit from having a required accuracy level on a test set, which may be a percentage lower than the original neural network.
Latest Examples
I’ll close with some cool examples from this year, which I found here. These examples demonstrate the hard work being put into HE neural network research, while also displaying the current lack of speed.
Llama 3 8B
In the NEXUS paper, they create a HE version of Meta’s mini LLM Llama-3-8B. Using four A100 GPUs, it can produce a 1-token output from an 8-token input in 52 seconds. So, one could say “this sentence is about 8 tokens long”, and wait 52 seconds to get the response “ok”.
Stable Diffusion
In the HE-Diffusion paper, they create a HE version of Stable Diffusion. The authors estimate that it would take ~5.72 days to run the model end-to-end using HE. However, they try their best to make it practical by doing some of the computation on the client-side, and doing some other model-specific tricks.
Latest Speeds For ResNet-20 on GPU
In the Cheddar paper, they reach a new state-of-the-art for HE neural networks on GPU by running ResNet-20 in 1.5 seconds (compared to the 316 seconds I mentioned earlier).
Agnostic Preacher
While I find HE neural networks to be very cool, I try not to let coolness prevent me from seeing possible negatives. The next couple of points will cover some of these possible negatives.
Not all Secret Computation is created Equal
Like most groundbreaking technologies, HE neural networks would be a double-edged sword. I’ll illustrate this quickly with contrasting use cases.
Positive Use Case
I encrypt the metrics from my health wearables and send it to a cloud server which hosts a HE neural network. I receive advice on how to improve my health, while also knowing that a virus can’t leak my health data and sell it to insurance companies.
Negative Use Case
A totalitarian dictator is trying to figure out how to trick his doubters into thinking that he is a God. He is out of ideas, and is about to give up. Then he asks an AI model, which is hosted as a HE neural network, and receives detailed advice. The advice includes videos of him walking on water, along with images of his political opponents committing crimes. The company hosting the AI model have no way of knowing this is happening, or ever knowing, because everything is encrypted. And no, the people tricked by the dictator don’t have enough access to education to be the “good guy with the AI”.
Want for Speed, Not Need
One legitimate negative to the HEPerf leaderboard I mentioned could be its environmental impact. The more we improve the efficiency of HE through software and hardware progress, the less energy it will use when deployed. For example, if more work went into neural network efficiency before ChatGPT was deployed, it would be using less energy right now. So perhaps we should hold off on buying the $250,000 server for our benchmarks until we’ve reached better efficiency.
Conclusion
HE neural networks are still very much impractical in 2024. The current state-of-the-art is to run a 270k parameter model in 0.125 seconds. This is a fast latency, but this model size is one million times smaller than the LLM applications that everyone has become so fond of. DARPA are currently running a challenge to drive HE acceleration though, and this is likely to produce multiple orders of magnitude of speedup. We don’t know when the teams in that challenge will have a buy-it-now link though, so we’ll need to wait and see.
If you would like me to do research like this for your company or research institution, check out the homepage of my website for more info about me, and please let me know!